자격증/정보처리기사 필기
[소프트웨어개발] 1. 데이터 입/출력 구현
염두리안
2023. 3. 5. 15:10
728x90
반응형

| 목차 |
| 036. 자료구조 (★★★) 037. 트리 (★★★) 038. 정렬 (★★★) 039. 검색-이분검색/해싱 (★★☆) 040. DB개요 (★★☆) 041. 데이터 입/출력 (★☆☆) 042. 절차형 SQL (★★☆) |
036. 자료구조 (★★★)
- 정의) 자료의 표현&그것과 관련된 연산 / 일련의 자료들을 조직, 구조화 / 어떤 자구에서도 필요한 모든 연산 처리 가능 / 자구에 따라 프로그램 실행시간 달라짐
- 분류
- 선형구조
- 배열
- 선형리스트 - 연속 리스트 / 연결 리스트
- 스택
- 큐
- 데크
- 비선형구조
- 트리
- 그래프
- 선형구조
- 배열(Array) : 동일 자료형의 데이터들이 같은 크기로 나열돼 순서를 갖고 있는 집합
- 정적인 자료 구조... 기억 장소 추가 어렵, 데이터 삭제 시 데이터가 저장되어 있던 기억장소는 빈 공간 ~> 낭비 / 첨자 이용 ~> 데이터 접근 / 반복적인 데이터 처리에 적합 /동일 이름 변수 사용 ~> 처리 간편
- 선형 리스트(Linear List) : 일정한 순서에 의해 나열된 자료구조... 연속 리스트(배열) / 연결 리스트(포인터)
- 연속 리스트) 배열처럼 연속되는 기억장소에 저장되는 자료구조 / 중간에 데이터 삽입하려면 연속된 빈 공간 있어야 하고, 삽입/삭제 시 자료 이동 필요함
- 연결 리스트) 연속적으로 배열 X, 임의의 기억 공간에서 기억하되 자료 항목의 순서에 따라 노드의 포인터 부분을 이용해 연결시킨 자료구조 / 노드 삭제, 삽입 용이 / 링크 부분이 필요... 순차 리스트에 비해 기억공간 이용 효율 좋지 X / 포인터 찾는 시간 때문에 접근 속도 느림 / 중간 노드 연결 끊어지면 다음 연결 노드 찾기 어렵
- 스택(Stack) : 리스트의 한쪽 끝으로만 자료 삽입, 삭제 작업 이뤄지는 구조(후입선출, LIFO)
- 응용분야) 함수 호출 순서 제어, 인터럽트 처리, 수식 계산&수식 표기법, 컴파일러 이용한 언어 변역, 부 프로그램 호출 시 복귀주소 저장, 서브루틴 호출 및 복귀주소 저장
- 오버플로 - 꽉 찬 상태에서 데이터 삽입 / 언더플로 - 데이터가 없는데 삭제 또 함

# 자료의 삽입
Top = Top + 1
If Top > M Then
Overflow
Else
X(Top) ← Iten
# 자료의 삭제
If Top = 0 Then
Underflow
Else
Item ← X(Top)
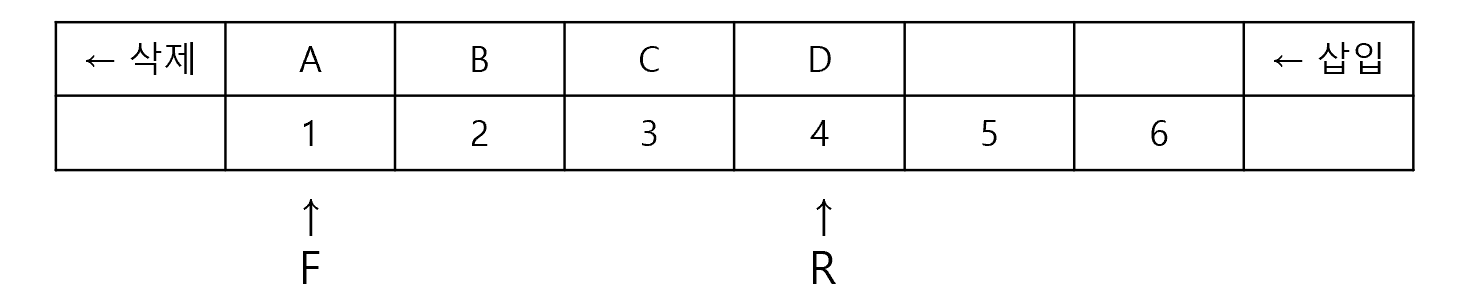
Top = Top-1- 큐(Queue) : 한 쪽에서 삽입, 한 쪽에서 삭제(선입선출, FIFO) / 시작, 끝을 표시하는 두 개 포인터 있음 / OS 작업 스케줄링에 사용
- 프런트 포인터(F) : 가장 먼저 삽입된 자료 기억 공간을 가리키는 포인터... 삭제 작업 시 사용
- 리어 포인터 (R) : 가장 마지막에 삽입된 자료가 위치한 기억공간 기리키는 포인터... 삽입 작업 시 사용
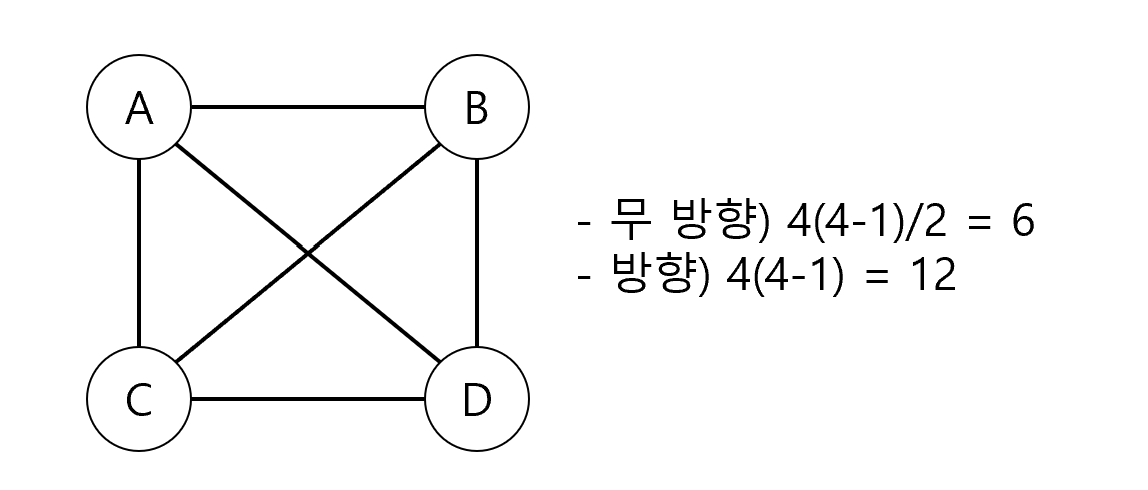
- 그래프(Graph) : 정점(V), 간선(E)의 두 집합으로 이뤄짐 / 간선 방향성 유무에 따라 방향, 무방향 그래프로 나뉨 / 통신망, 교통망, 이항관계, 연립방정식, 유기화학 구조식 등 / 트리는 사이클이 없는 그래프
- 방향/무방향 그래프의 최대 간선 수
- 무방향 그래프 최대 간선 수) n(n-1)/2
- 방향 그래프 최대 간선 수) n(n-1)
037. 트리 (★★★)
- 개요) 정점(노드)과 선분(가지)를 이용해 사이클을 이루지 않도록 구성한 그래프의 특수 형태 / 노드 - 하나의 기억공간 / 링크 - 연결선 / 족보, 조직도 등 표현하기 좋음
- 근노드(Root Node) : 최상위 노드
- degree(차수) : 각 노드에서 뻗어나온 가지수
- 단말노드(Terminal Node) / 잎노드(Leaf Node) : 자식이 하나도 없는 노드 / 차수 = 0
- 자식노드 : 어떤 노드(부모노드)에 연결된 다음의 노드 / 형제노드 : 부모 같은 노드
- 트리의 디그리 : 노드들의 차수 중, 가장 많은 수
- 트리의 운행법) 트리를 구성하는 각 노드들을 찾아가는 방법
- Preoder) Root > Left > Right
- A > B > D > H > I > E > C > F > G
- Inorder) Left > Root > Right
- H > D > I > B > E > A > F > C > G
- Postorder) Left > Right > Root
- H > I > D > E> B > F > G > C > A
- Preoder) Root > Left > Right

- 수식의 표기법) 산술식 계산하기 위해 기억공간에 기억시키는 방법... 이진트리에서 많이 사용
- 전위표기법(PreFix) : 연산자 > Left > Right, +AB
- 중위표기법(InFix) : Left > 연산자 > Right, A+B
- 후위표기법(PostFix) : Left > Right > 연산자, AB+
- 변환해보기!
| ## Infix → Postfix, Prefix ## X = A / B * (C + D) + E - Prefix 1. 연산 우선순위에 따라 괄호로 묶기 ( X = ((A / B) * ( C + D ) ) + E) 2. 연산자를 해당 괄호 앞으로 옮김 (X + ( * ( / (AB) + (CD) ) E) ) 3. 필요없는 괄호 제거 X + * / A B + C D E - PostFix 1. 연산 우선순위에 따라 괄호 묶기 (X = ( ( A / B) * ( C + D ) ) + E ) ) 2. 연산자를 해당 괄호 뒤로 옮김 (X ( (A B) / (C D) + ) * E ) + ) = 3. 필요없는 괄호 제거 X A B / C D + * E + = |
| ## Postfix&Prefix → Infix ## A B C - / D E F + * + - Postfixt 1. 인접한 피연산자 두개와 오른쪽의 연산자를 괄호로 묶음 ( (A (B C -) /) (D (E F +) *) +) 2. 연산자를 해당 피연산자 가운데로 이동 ((A / B - C)) + (D * (E + F))) 3. 필요없는 괄호 제거 (A / (B-C) + D * (E + F) - Prefix 1. 인접한 피연산자 두개와 왼쪽의 연산자를 괄호로 묶음 (+ (/ A (- B C) ) ( * D ( + E F) ) ) 2. 연산자를 해당 피연산자 사이로 이동 ((A/(B-C)) + (D*(E+F))) 3. 필요없는 괄호 제거 A/(B-C)+D*(E+F) |
038. 정렬 (★★★)
- 삽입 정렬(Insertion Sort) : 가장 간단한 정렬... 이미 순서화된 파일에 새로운 하나의 레코드를 순서에 맞게 삽입시켜 정렬 / 평균, 최악 시간 복잡도 = O(n^2)

- 쉘 정렬(Shell Sort) : 삽입정렬 확장 개념 / 입력 파일이 부분적으로 정렬되어 있을 때 / 평균 시간 복잡도 = O(n^1.5), 최악 시간 복잡도 = O(n^2) / 키워드 "매개변수"
- 선택 정렬(Selection Sort) : n개의 레코드 中, 최소값 찾아 첫 번째 레코드 위치에 놓고 나머지 (n-1)개 중 다시 최소값을 찾아 두 번째 레코드에 놓는 것 반복 / 평균, 최악 시간 복잡도 = O(n^2)

- 버블 정렬(Bubble Sort) : 인접한 두 개의 레코드 키 값 비교... 그 크기에 따라 레코드 위치를 서로 교환하는 정렬 방식 / 평균, 최악 시간 복잡도 = O(n^2)
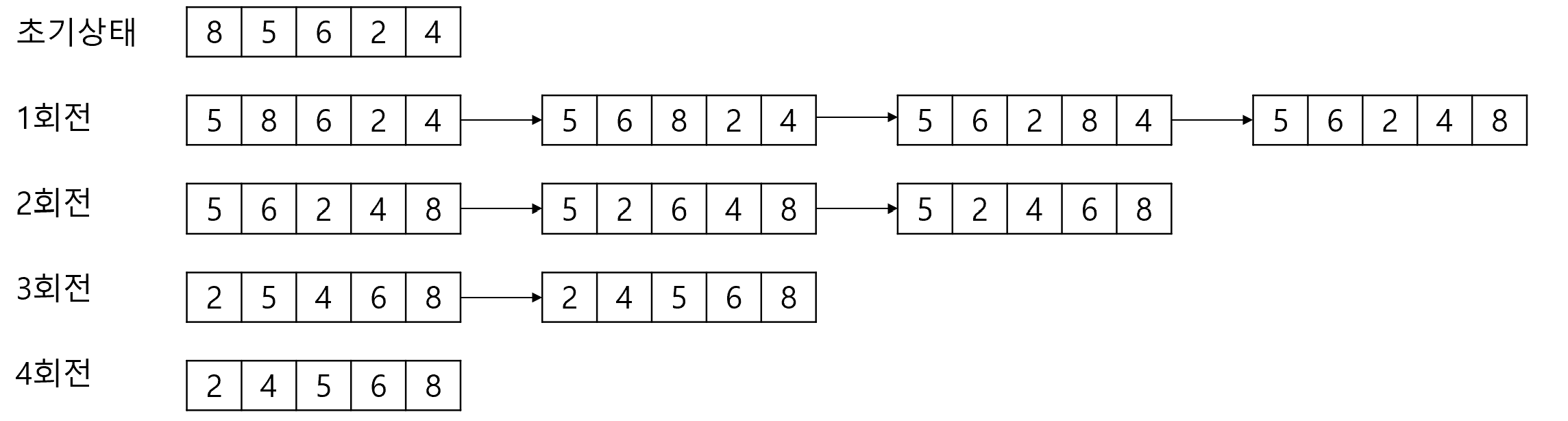
- 퀵 정렬(Quick Sort) : 레코드의 많은 자료 이동 없애고 하나의 파일을 부분적으로 나눠가면서 정렬 / 작은 값은 왼쪽, 큰 값은 오른쪽 서브파일에 분해 / 위치 상관없이 임의의 키를 분할 원소로 사용 가능 / 정렬 중 젤 빠름 / 분할, 정복 통해 자료 정렬 / 평균 시간 복잡도 = O(nlogv2 n), 최악 시간 복잡도 = O(n^2)
- 힙 정렬(Heap Sort) : 전이진 트리(Complete Binary Tree) 이용한 정렬 방식 / 평균, 최악 시간 복잡도 = O(nlongv2 n)
- 주어진 파일의 레코드를 전이진트리로 구성 → 전이진 트리의 노트 역순으로 자식노드, 부모노드 비교해 큰 값을 위로 올림 → 교환된 노드를 다시 검토해 과정 반복
- 2-Way 합병 정렬(Merge Sort) : 이미 정렬되어 있는 두 개의 파일을 한 개의 파일로 합병하는 병렬 방식 / 평균, 최악 시간 복잡도 = O(nlongv2 n)
- 두 개의 키들을 한 쌍으로 해서 각 쌍에 대해 순서 정함 → 순서대로 정렬된 각 쌍의 키들 합병해 하나의 정렬된 서브리스트로 만듦 → 과정에서 정렬된 서브리스트들을 하나의 정렬된 파일이 될 때까지 반복
- 예) 71, 2, 38, 5, 7, 61, 11, 26, 53, 42
- (71, 2), (38, 5), (7, 61), (11, 26), (53, 42) → (2, 71), (5, 38), (7, 61), (11, 26), (42, 53)
- ((2, 71)(5, 38)), ((7, 61)(11, 26)), (42, 53) → (2, 71, 5, 38), (7, 61, 11, 26), (42, 53) → (2, 5, 38, 71), (7, 11, 26, 61), (42, 53)
- (2, 5, 38, 71, 7, 11, 26, 61), (42, 53) → (2, 5, 7, 11, 26, 38, 61, 71), (42, 53)
- (2, 5, 7, 11, 26, 38, 61, 71, 42, 53) → 2, 5, 7, 26, 38, 42, 53, 61, 71
- 기수 정렬(Radix Sort, Bucket Sort) : 큐를 이용해 자릿수 별로 정렬 / 레코드 키 값 분석 ~> 같은수(문자)끼리 그 순서에 맞는 버킷에 분배 후 버킷 순서대로 레코드를 꺼내 정렬 / 평균, 최악 시간 복잡도 = O(dn)
039. 검색-이분검색/해싱 (★★☆)
- 이분 검색) 전체 파일을 두 개의 서브 파일로 분리해 가면서 Key 레코드를 검색하는 방식 / 반드시 순서화된 파일어야 검색 가능 / 거듭할 때마다 검색 데이터 수 반토막... 효율 좋고 탐색 시간 적게 소요됨
- 중간 레코드 번호 M = (F+L) / 2
- 해싱(Hashing)) 기억공간 해시 테이블 할당, 해시 함수를 이용해 레코드 키에 대한 해시 테이블 내 홈 주소 계산 후 주어진 레코드를 해당 기억장소에 저장 or 검색 수행
- 해시테이블 : 레코드를 한 개 이상 보관할 수 있는 버킷들로 구성된 기억공간... 보조/주기억장치 둘 다 구성 가능
- 버킷(Bucket) : 하나의 주소를 갖는 파일의 한 구역 / 버킷 크기 = 같은 주소에 포함될 수 있는 레코드 수
- 슬롯(Slot) : 한 개 레코드를 저장할 수 있는 공간 / n개 슬롯이 모여 하나의 버킷 생성
- Collision(충돌현상) : 서로 다른 두 개 이상의 레코드가 같은 주소를 갖는 것
- Synonym : 충돌로 인해 같은 홈 주소를 갖튼 레코드들의 집합
- Overflow : 계산된 홈 주소의 버킷 내에 저장할 기억공간이 없는 상태 / 버킷을 구성하는 슬롯이 여러 개일 경우 충돌은 발생해도 오버플로는 발생 안할 수 있음
- 해싱 함수(Hashing Function)
- 제산법(Division) : 레코드 키(K)를 해시테이블의 크기보다 큰 수 중에서 가장 작은 소수(Prime, Q)로 나눈 나머지 홈 주소로 삼는 방식 / h(K) = K mod Q
- 제곱법(Mid-Square) : 레코드 키 값을 제곱 후 그 중간 부분의 값을 홈 주소로 함
- 폴딩법(Folding) : 레코드 키 값을 여러 부분으로 나눈 후 각 부분의 값을 더하거나 XOR한 값을 홈 주소로 함
- 기수 변환법(Radix) : 키 숫자의 진수를 다른 진수로 변환... 주소 크기를 초과한 높은 자릿수는 절단 후 다시 주소 범위에 맞게 조정
- 대수적 코딩법(Algebraic Coding) : 키 값을 이루고 있는 각 자리의 비트 수를 한 다항식 계수로 간주... (생략)
- 숫자 분석법(Digit Analysis, 계수 분석법) : 키 값을 이루는 숫자의 분포를 분석 ~> 비교적 고른 자리를 필요한 만큼 택해서 홈 주소로 함
- 무작위법(Random) : 난수를 발생시켜 나온 값을 홈 주소로 함
- 해시테이블 : 레코드를 한 개 이상 보관할 수 있는 버킷들로 구성된 기억공간... 보조/주기억장치 둘 다 구성 가능
040. DB개요 (★★☆)
- 데이터저장소) 데이터들을 논리적인 구조로 조직화 or 물리적인 공간에 구축한 것(논리/물리 데이터저장소로 구분)
- DB 특징) 통합된 데이터(Integrated, 자료 중복 배제) / 저장된 데이터(stored) / 운영 데이터(Operational) / 공용 데이터(Shared)
- DBMS) DB 구성, 접근방법, 유지관리에 대한 모든 책임을 짐 / 정의, 조작, 제어 기능
- 정의기능(Definition) : 저장될 데이터의 Type, 구조, 이용방식, 제약조건 등을 명시하는 기능
- 조작기능(Manipulation) : 데이터 검색, 갱신, 삭제, 삽입 등을 체계적으로 하기 위해 사용자-데베 간 인터페이스 수단 제공
- 제어기능(Control) : 무결성, 권한 검사, 병행 제어
- 장점) 논리적, 물리적 독립성 보장 / 공간 절약 / 공동 이용 / 무결성, 일관성, 보안 유지 / 표준화 / 통합 관리 / 최신의 데이터 유지 / 실시간 처리
- 논리적 독립성 : 응용프로그램 - 데이터베이스 독립 ~> 데이터 논리적 구조 변경해도 응용프로그램은 변경 X
- 물리적 독립성 : 응용프로그램 - 보조기억장치 독립 ~> DB 시스템 성능향상 위해 새로운 디스크 도입해도 응용프로그램에는 영향 X
- 단점) 전문가 부족(?) / 전산화 비용 증가 / 과부하 발생 / 파일의 백업과 회복이 어렵 / 시스템 복잡
- 스키마(Schema) : DB 구조, 제약조건에 관한 전반적인 명세를 기술한 메타데이터 집합 / DB를 구성하는 데이터개체(Entity), 속성(Attribute), 관계(Relationship), 데이터 조작 시 데이터 값들이 갖는 제약 조건 정의
- 외부스키마 : 사용자, 응용프로그래머가 각 개인 입장에서 필요로 하는 DB를 논리적 구조로 정의
- 개념스키마 : DB의 전체적인 논리적 구조... 모든 응용프로그램, 사용자가 필요로 하는 데이터를 종합한 조직 전체 DB / 하나만 존재 / 개체 간 관계&제약조건, DB 접근권한&보안&무결성 규칙 명세
- 내부스키마 : 물리적 저장장치 입장에서 본 DB 구조 / 실제 DB에 저장될 레코드 형식 정의, 저장 데이터 항목의 표현 방법, 내부 레코드의 물리적 순서 나타냄
041. 데이터 입/출력 (★☆☆)
- 개요) DB에 데이터 입출력하는 작업
- SQL) 은 3과목에서 봅쉬다~~~ / 정의어(DDL), 조작어(DML), 제어어(DCL)
- 데이터 접속(Data Mapping, DBMS 접속) : 기능 구현을 위해 프로그래밍 코드랑 DB 데이터 연결하는 것
- SQL Mapping : SQL직접 입력해 DBMS 데이터 접속 / JDBC, ODBC, MyBatis
- ORM : 객체지향 프로그래밍 객체와 관걔형 DB 데이터 연결 / JPA, Hibernate, Django
- 트랜잭션(Transaction)) DB상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업 단위 or 한꺼번에 모두 수행되어야 할 일련의 연산들 / TCL - 트랜잭션 제어 위한 명령어
- COMMIT : 트랜잭션 정상적 종료 ~> 변경 내용 DB에 저장
- ROLLBACK : 하나의 트랜잭션 처리가 비정상 종료되어 DB 일관성이 깨졌을 때 ~> 모든 변경 작업 취소, 이전 상태로 되돌림
- SAVEPOINT(=CHECKPOINT) : 롤백할 위치인 저장점을 지정하는 명령어
042. 절차형 SQL (★★☆)
- 개요) C, Java 등 프로그래밍 언어 같이 연속적인 실행, 분기, 반복 등 제어가 가능한 SQL / 일반적인 프로그래밍 언어에 비해 효율 떨어지나 단일 SQL 문장으로 처리하기 어려운 연속작업 처리에 적합 / DBMS엔진에서 직접 실행 ~> 입출력 패킷 적음 / 종류 - 프로시저(특정기능 수행하는 트랜잭션 언어), 트리거(DB에서 이벤트 발생 시 관련 작업 자동 수행), 사용자 정의 함수(SQL사용해 일련 작업을 연속적으로 처리, 리턴 사용해 처리결과 단일값으로 반환)
- 절차형 SQL 테스트와 디버깅) 테스트 전 생성을 통해 구문오류(Syntax Error), 참조오류 확인 / SQL 특성상 오류&경고 메시지 자세히 출력 X ~> SHOW 명령어 통해 내용 확인 후 문제 수정 / 디버깅 통해 로직 검증, 결과 통해 최종 확인 / 절차형 SQL의 디버깅은 실제 DB에 변화를 줄 수 있는 삽입, 변경 관련 SQL을 주석처리, 출력문을 이용해 화면에 출력하여 확인
- 쿼리 성능 최적화) APM(성능측정도구) 사용 / 최적화할 쿼리에 대해 옵티마이저(최적 경로 찾아주는 모듈, DBMS 내장됨)가 수립한 실행 계획 검토, SQL 코드&인덱스 재구성
728x90
반응형